
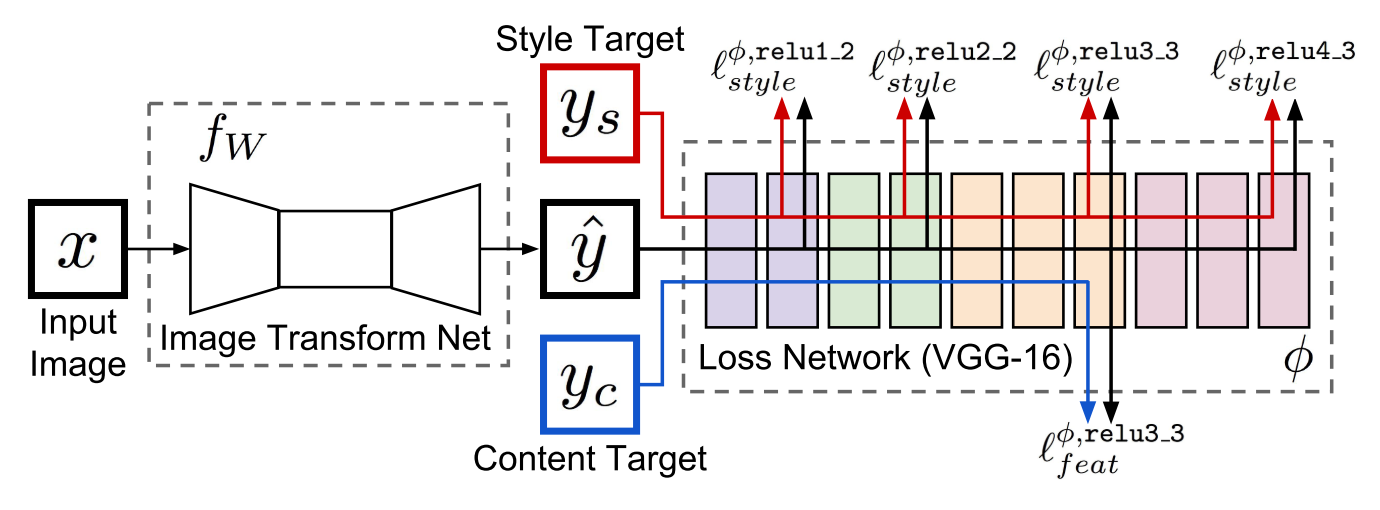
Johnson, J., Alahi, A., & Fei-Fei, L. (2016, October). Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision (pp. 694-711). Springer, Cham.
path = untar_data(URLs.IMAGENETTE)
db = DataBlock(blocks=(ImageBlock, ImageBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.01),
get_x=noop, get_y=noop,
item_tfms=Resize(256),
batch_tfms=Normalize.from_stats(0.5*torch.ones(3), 0.5*torch.ones(3)))
dls = db.dataloaders(path, bs=4, num_workers=4)
dls.show_batch()

For style transfer we have to choose any image as a style target and normlalize it with the imagenet_stats.
def get_style_target(artist, size=256, **kwargs):
r = requests.get(artists_sources[artist], stream=True)
style_target_img = PILImage.create(r.content)
p = Pipeline([ToTensor,
Resize(size, **kwargs),
IntToFloatTensor,
Normalize.from_stats(*imagenet_stats, cuda=False)])
return p(style_target_img), p
style_target, p = get_style_target('picasso')
p.decode(style_target)[0].show(figsize=(10,10));

These are the original weights used in the paper.
!wget http://cs.stanford.edu/people/jcjohns/fast-neural-style/models/vgg16.t7 -O vgg16.t7
The PerceptualLoss module computes the feature loss based on feture_layer and the style loss on the style_layers_names.
style_target_test = TensorImage(torch.rand(1, 3, 256, 256)*2-1)
feature_loss = PerceptualLoss(style_target_test, renormalize=True, style_weight=1, bs=4)
input = TensorImage(torch.rand(2, 3, 256, 256)*2-1).cuda()
target = TensorImage(torch.rand(2, 3, 256, 256)*2-1).cuda()
loss = feature_loss(input, target)
loss
Test that the style image is properly normalized
style_unnorm = TensorImage(torch.rand(1, 3, 256, 256))
style_imagenet = Normalize.from_stats(*imagenet_stats, cuda=False)(style_unnorm)
style_norm = style_unnorm*2-1
feature_loss = PerceptualLoss(style_imagenet, renormalize=True, feature_weight=0, cuda=False)
target = TensorImage(torch.rand(1, 3, 256, 256)*2-1)
loss = feature_loss(style_norm, target)
test_eq(loss, 0)
Test that cuad=True works
style_target_test = TensorImage(torch.rand(1, 3, 256, 256)*2-1)
feature_loss = PerceptualLoss(style_target_test, renormalize=True)
input = TensorImage(torch.rand(1, 3, 256, 256)*2-1).cuda()
target = TensorImage(torch.rand(1, 3, 256, 256)*2-1).cuda()
loss = feature_loss(input, target)
loss
style_target_test = TensorImage(torch.rand(1, 3, 256, 256)*2-1)
feature_loss = PerceptualLoss(style_target_test, renormalize=True, bs=4)
input = TensorImage(torch.rand(4, 3, 256, 256)*2-1).cuda()
target = TensorImage(torch.rand(4, 3, 256, 256)*2-1).cuda()
loss = feature_loss(input, target)
loss
style_target_test = TensorImage(torch.rand(1, 3, 256, 256)*2-1)
feature_loss = PerceptualLoss(style_target_test, renormalize=True, style_weight=1e5, feature_weight=1)
target = TensorImage(torch.rand(1, 3, 256, 256)*2-1).to('cuda')
loss = feature_loss(target, target)
loss
style_target_test = TensorImage(torch.rand(1, 3, 256, 256)*2-1)
feature_loss = PerceptualLoss(style_target_test, renormalize=True, style_weight=1, bs=4)
input = TensorImage(torch.rand(4, 3, 256, 256)*2-1).cuda()
target = TensorImage(torch.rand(4, 3, 256, 256)*2-1).cuda()
loss = feature_loss(input, target)
loss
We use LBFGS optimization to find the images that mimimize the style loss.


We can also visualize images that minimize the feature reconstruction loss at different layers

jrb = JohnsonResBlock(32)
x = torch.randn(4, 32, 16, 16)
y = jrb(x)
test_eq(y.shape, x.shape)
style_transfer_generator = ResnetGenerator()
x = torch.randn(1, 3, 256, 256)
y = style_transfer_generator(x)
y.shape, y.max(), y.min()
style_target, _ = get_style_target('picasso')
sgc = ShowGraphCallback()
picasso_learn = style_learner(dls, style_target=style_target, cbs=sgc, plkwargs={'style_weight': 0.5, 'feature_weight':5})
with picasso_learn.removed_cbs(sgc):
picasso_learn.fit(1, lr=1.e-3)
picasso_learn.fit(7, lr=1.e-3)
picasso_learn.show_results()

db = DataBlock(blocks=(ResImageBlock(72), ResImageBlock(288)),
get_items=get_image_files,
get_x=noop, get_y=noop,
batch_tfms=Normalize.from_stats(0.5*torch.ones(3), 0.5*torch.ones(3)))
dls = db.dataloaders(path, bs=4, num_workers=4)
dls.show_batch()
b = dls.one_batch()
learn = superres_learner(dls)
learn.fit(16, lr=1e-3, wd=0)
learn.show_results()

db = DataBlock(blocks=(ResImageBlock(36), ResImageBlock(288)),
get_items=get_image_files,
get_x=noop, get_y=noop,
batch_tfms=Normalize.from_stats(0.5*torch.ones(3), 0.5*torch.ones(3)))
dls = db.dataloaders(path, bs=4, num_workers=4)
dls.show_batch()
b = dls.one_batch()
learn = superres_learner(dls, superres_factor=8)
learn.fit(16, lr=1e-3, wd=0)
learn.show_results()
